
自然语言处理主要解决什么问题,有哪些特点?
对于自然语言理解,有两种定义。第一种是计算机能够将所说的语言映射到计算机内部表示;另一种是基于行为的,你说了一句话,计算机做出了相应行为,就认为计算机理解了自然语言。后者的定义,更广为采用。
语言具有不完全规律性、可组合性,是一个开放的合集,同时在使用时又需要基于环境、联系实践知识,因此在计算机里去实现与人一样的语言使用能力是一件非常具有挑战性的事情。首先,语言的不完全规律性和组合性,就意味着如果在目前的计算机上去实现,会产生组合爆炸;还有,如果需要语言做比喻,去联系到实践环境,就意味着要做全局的、穷举的计算。如果通过现代计算机来做,非常复杂,几乎不太可能。其本质原因是,目前在计算机上去实现东西一定需要数学模型,而语言的使用还不清楚是否能够用数学模型去刻画。

目前最好的自然语言处理的方法是机器学习,包括深度学习。也就是,基于机器学习,并在一定程度上把人的知识加进来,并参考人脑的机理,从而构建更好的机器学习办法。如今越来越多的大数据也使得我们能够更好去做自然语言处理。
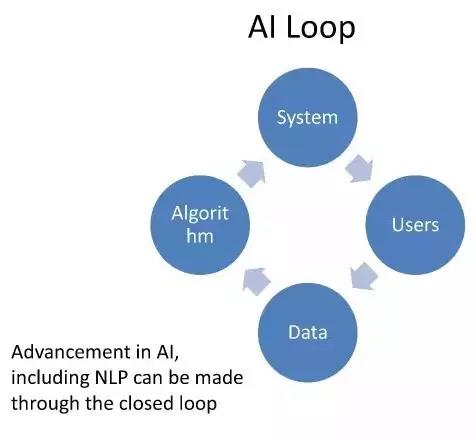
无论是自然语言处理,还是人工智能的其他领域,都形成了一个闭环机制。比如,开始有一个系统,然后有用户产生大量的数据,之后基于数据,开发好的算法,提高系统的性能。如果能够闭环跑起来,就可以去收集更多的数据,可以开发出更好的机器学习算法,使得人工智能系统的性能能够不断提升。这个人工智能闭环是现代人工智能技术范式里最本质的一个现象,对于自然语言处理也不是例外。我们可以通过闭环,不断去开发新的算法,提高自然语言处理系统的性能。
所有的自然语言处理的问题都可以分类成为五大统计自然语言处理的方法或者模型,即分类、匹配、翻译、结构预测,马尔可夫决策过程。分类主要有文本分类和情感分类,匹配主要有搜索、问题回答、对话(主要是单轮对话);翻译主要有机器翻译,语音识别,手写识别,单轮对话;结构预测主要有专门识别,词性标注,句法分析,文本的语义分析;马可夫决策过程可以用于多轮对话。各种各样的自然语言处理的应用,都可以模型化为这五大基本问题,基本能够涵盖自然语言处理相当一部分或者大部分的技术。

语言处理,在一定程度上需要考虑技术上界和性能下界的关系。现在的自然语言处理,最本质是用数据驱动的方法去模拟人,通过人工智能闭环去逼近人的语言使用能力。但是,这种技术并没有真正实现人的语言理解机制。自然语言处理的技术会不断提高,但是是不是都能够达到我们每一个应用要求的性能的下界,就不好说了,要看未来的发展了。
自然语言处理的最新技术
1、 问答系统
问答系统有很多,这里面牵扯到几个技术,在线的时候要做匹配和排序,现在最先进的技术都是用深度学习技术,比如 IBM 的 Watson。典型的办法就是把问答用FAQ索引起来,与搜索引擎相似,如果来了一个新问题,有一大堆已经索引好的FAQ,然后去做一个检索(字符上的匹配),之后逐个去做匹配,判断问句与回答的匹配如何。往往匹配的模型有多个,再去将候补做一个排序,把最有可能的答案排在前面,往往就取第一个作为答案返回给用户。
2、 图像检索
同样也是基于深度学习技术,跨模态地把文本和图片联系起来。
3、 自然语言对话
自然语言对话是用另外一种技术,用生成式的模型去做自然语言对话。大量的聊天系统是这么做的,输入一句话,里面准备了大量的FAQ,搜索到一个最相关的回答,反馈给你。这叫做基于检索的自然语言问答系统。
4、 机器翻译
机器翻译的历史被认为与自然语言处理的历史是一样的。最近,深度学习,更具体的就是序列对序列学习,被成功地运用到机器翻译里,使得机器翻译的准确率要大幅度提升。谷歌的神经机器翻译系统是一个非常强大的系统,需要很多训练数据和强大计算资源。这个seqto seq模型有八层的编码器和八层的解码器,整个网络非常深。它还用了各种新技术,比如注意力技术、并行处理技术、还有模型分割和数据分割等,使得翻译的准确率已经超过了传统的统计机器翻译。
目前,几个最基本的应用,包括语音识别,就是一个序列对序列学习的问题,就是翻译的问题,目前准确率是95%左右,那么已经比较实用了。单轮对话往往可以变成一个分类问题,或者结构预测问题,就是通过手写一些规则或者建一些分类器,可以做的比较准,但多轮对话还很不成熟,只有在特定场景下能做的比较好。文本的机器翻译水平在不断提高,深度学习在不断进步,越来越接近人的专业水平,但只是在一些特定场景下。人的语言理解是一个非常复杂的过程,序列对序列实际上是一种近似,现在这种技术能够去无穷尽的逼近人,但是本质上还是跟人的做法不一样的,但完全去替代人,还是不太可能。
自然语言处理方向的发展趋势
语音识别、机器翻译已经起飞,大家现在开始慢慢在用,但是真正对话的翻译还很困难,还有很长的路要走,但是也说不定能够做得很好。并不是说序列对序列就没有问题需要解决了,还有细致的问题,比如不常用的单词、语音识别、翻译还是做得不是很好,因为现在机器学习的方法是基于统计的,需要看到甚至多次重复看到一些东西,才能够掌握这些规律。
这块有很多技术将帮助解决一些问题,使得机器翻译或语音识别技术不断提高,但是完全彻底的解决还是比较困难,因为这是这种方法带来的一个局限性。单轮的问答,特别是场景驱动的单轮的问答,可能慢慢会开始使用,但是多轮对话技术还是比较难,这些是否能够用马尔科夫决策过程去模拟或者近似还不是很清楚,但随着多轮对话在任务驱动的简单场景,有了更多的数据,是有可能做的越来越好。